Workflow
Quality assurance
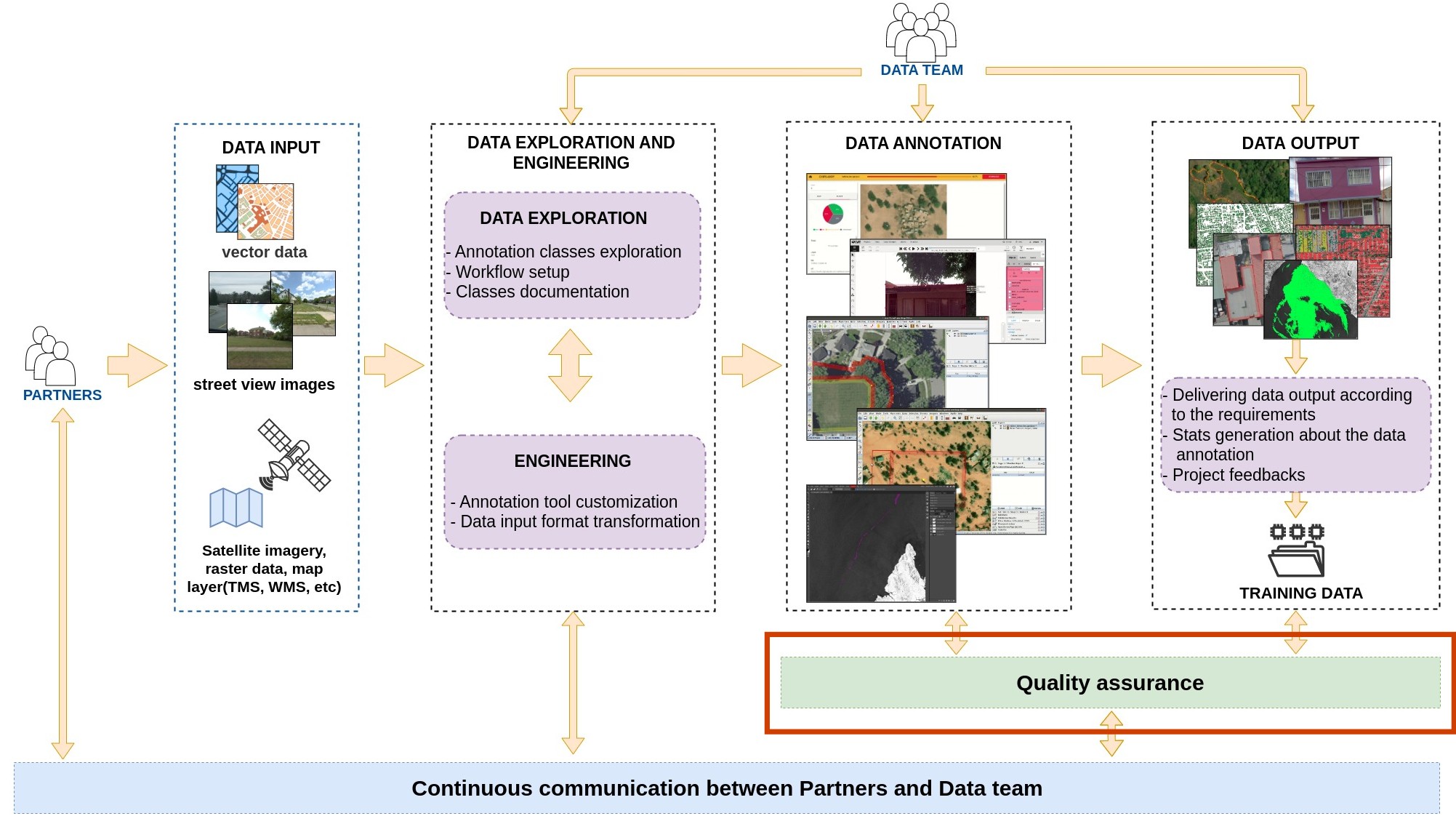
Data quality is directly related to the effectiveness of AI/ML models, so ensuring data quality is very important. The Data team has embedded the Quality Assurance (QA) process in its workflow to guarantee continuous improvement of the training data during the data annotation and data output processes.
The best practices that the Data team follows in our QA process to deliver high-quality training data are:
- Internal revision; the Data team does a manual data validation of a test batch of the annotated data to ensure that all the annotators are following the same perspective in the labeling and to find possible common issues in advance.
- Feedback from partners; the Data team sends one first dataset of the annotation to have partners review. Feedback is then incorporated to improve annotation quality.
- Validations scripts; in addition to manual data revision, the Data team writes scripts to automatically find issues in the data and problems that can escape the human eyes, thus speeding up the data validation.