Methodology
Training dataset creation
Image tiles downloading
Two categories of datasets, ‘school’ and ‘not-school’, were generated as the training dataset for the machine learning model. We randomly sampled half of the school geolocations from the validated “confirmed schools”, and generated 5,904 tiles as “school” training dataset in the following table. The not-school category is not as trivial. This category can contain forest, grassland or agricultural fields without any buildings, among others. It can also be a building complex or facility that looks very similar to “school” from space, e.g. hospitals, market places, courthouses etc.
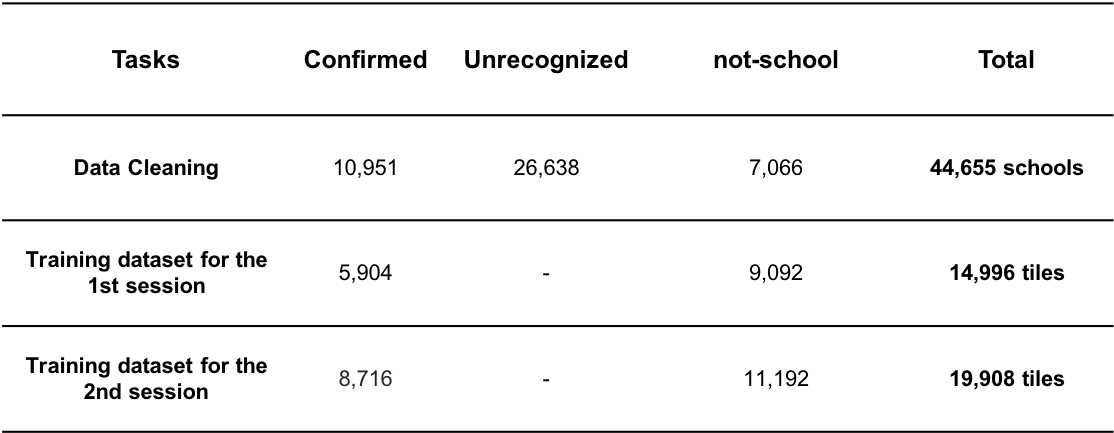
To enrich the “not-school” category, and allow our machine learning algorithm to detect real schools more accurately, we queried available hospital, farmlands, parks, courthouses and marketplaces from OpenStreetMap and added them to the “not-schools” category. We ended up with 9,092 ‘not-school’ tiles, see the above table. Through the machine learning model training iterations, we learned that the model was over-confident in certain areas, and therefore we adjusted the training dataset accordingly. For instance, we randomly included more schools as well as purposely added more regular building tiles that are not schools. See the detailed table for the training dataset for the different sessions.
Above image tiles creation training was done using Geokit and a customized tile downloading python script we created. However it can be done directly using Label Maker.
Training dataset split
To assess the model performance fairly, our training dataset of two categories, school and not-school tiles, are then split into 70:20:10 ratio as train, validation and test datasets. We randomly selected 70% of tiles to train the model, the remaining 20% was used to validate the model. The training set was seen and used by the model intensively to train the school classifier, and the validation set is occasionally seen and used to fine-tune the classifier. However, the last 10% of test dataset was not seen by the model, and it acts as the golden standard dataset to evaluate the model performance.